
NOSQL бази данни
При днешните бизнес изисквания релационните бази данни започват да срещат трудности , въпреки че все още са тези който крепят основните бизнес операции. Като основна пречка при релационния модел се явяват проблеми като възможности за гъвкаво скалиране , ангажиране на приложенията ползващи релационния модел с допълнителна логика , проблеми свързани с кеширането, възможности за адаптиране и изменение както и нарушаване на релационния модел като метод за оптимизация. Именно тези недостатъци са причината за появата на noSQL. NoSQL се интерпретира като „не само SQL“и в никакъв случай не отхвърля релационния модел, по скоро предлага различен поглед върху начините за съхранение да данните и решава най-често срещаните проблеми в релационния модел.
Релационния модел се характеризира с това че е структуриран и е базиран на т.н. таблици. Таблицата сама по себе си е изградена от колони , имената на колоните се наричат атрибути. Съвкупността на всички атрибути на една таблица се нарича „Схема на Релация“. Съвкупността от всички „Схеми на релации“ в рамките на една база от данни се нарича „Схема на Базата от данни“.
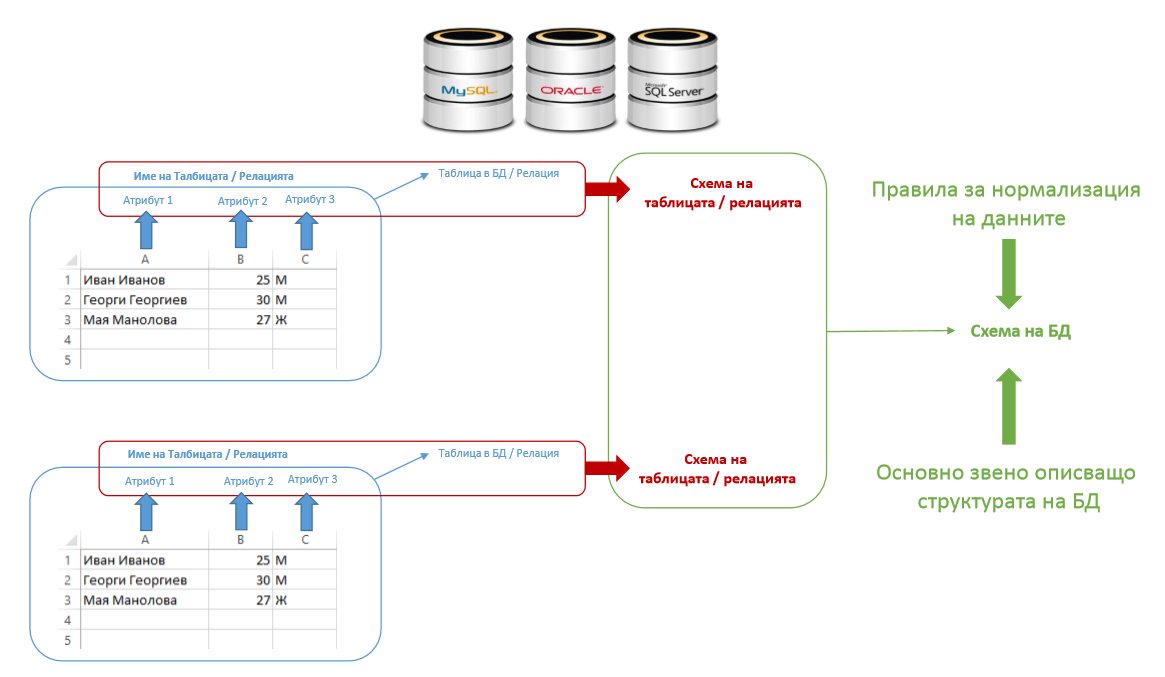
За да се предотвратят аномалии в данните, върху схемата на базата от данни се прилагат т.н. правила за нормализация на данните. Тези правила гарантира, че съхраняваните в базата данни ще са във нормална форма.
В noSQL модела са залегнали различни модели за представяне и съхранение на данните според това за какво са предназначени. Именно различните модели за съхранение и представяне на данните са причина за появата на множество различни noSQL БД със специфична употреба. Най-често използваните методи за съхранение на данните в noSQL са:
 Документен модел. - Тук се свързват всеки ключ със сложна структура от данни, известна като документ. Документите съдържат едно или повече полета, като всяко поле съдържа стойност (например стринг, дата, масив и т.н.). Вместо като при релационните бази данни записите да се разпределят в множество колони и таблици, тук всеки запис и асоциираните с него данни се съхраняват заедно в един документ. Това опростява достъпът до данните и намалява необходимостта от свързани и сложни транзакции. Всеки документ може да съдържа различни полета, което е много полезно при моделиране на неструктурирани данни. Също улеснява разработката на приложения, например чрез добавянето на нови полета. Пример за такава БД е Lotus Domino
Документен модел. - Тук се свързват всеки ключ със сложна структура от данни, известна като документ. Документите съдържат едно или повече полета, като всяко поле съдържа стойност (например стринг, дата, масив и т.н.). Вместо като при релационните бази данни записите да се разпределят в множество колони и таблици, тук всеки запис и асоциираните с него данни се съхраняват заедно в един документ. Това опростява достъпът до данните и намалява необходимостта от свързани и сложни транзакции. Всеки документ може да съдържа различни полета, което е много полезно при моделиране на неструктурирани данни. Също улеснява разработката на приложения, например чрез добавянето на нови полета. Пример за такава БД е Lotus Domino
 Графичен модел. - Той използва структури от графи с възли, рамена и свойства, за да представя данните. По-точно данните се моделират като мрежа от връзки между определени елементи. Този модел не е особено интуитивен, но е много добър за моделиране на връзки между елементи в едно приложение. Това е особено полезно при социалните мрежи.
Графичен модел. - Той използва структури от графи с възли, рамена и свойства, за да представя данните. По-точно данните се моделират като мрежа от връзки между определени елементи. Този модел не е особено интуитивен, но е много добър за моделиране на връзки между елементи в едно приложение. Това е особено полезно при социалните мрежи.
 Ключ-стойност модел. - Това са най-простите NoSQL базите данни. Всяко едно нещо в базата данни се съхранява като определящо име (или „ключ“), заедно с неговата стойност. Стойността обаче е невидима за системата – данните могат да бъдат търсени само по ключа. Този модел може да е полезен при неструктурирани данни.
Ключ-стойност модел. - Това са най-простите NoSQL базите данни. Всяко едно нещо в базата данни се съхранява като определящо име (или „ключ“), заедно с неговата стойност. Стойността обаче е невидима за системата – данните могат да бъдат търсени само по ключа. Този модел може да е полезен при неструктурирани данни.
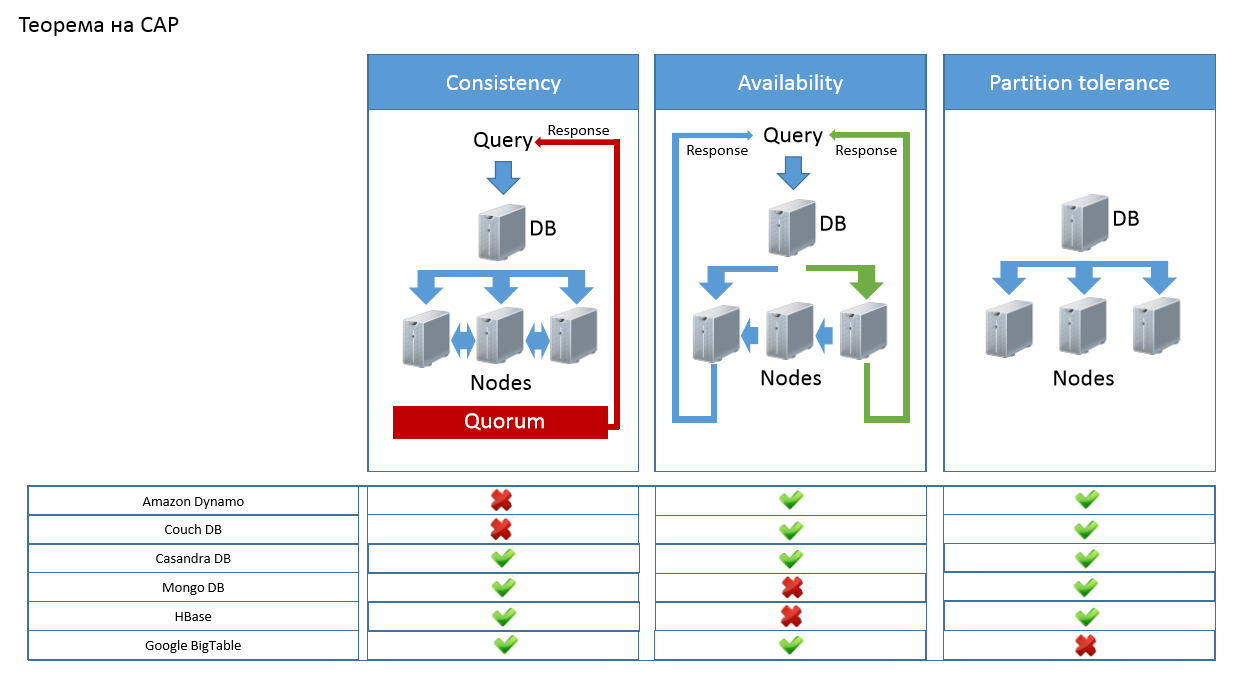
Релационния модел е най-широко разпространен в момента и милиони приложения работят с него. Въпреки това все по често се проявяват проблеми свързани главно с нарастването на данните и натоварването. Когато става въпрос за разпределени системи – клъстеризация на БД се въвежда понятието теорема на CAP. Теоремата на CAP гласи всяка разпределена система от БД се основава на три основни стълба – консистентност на данните , наличност на данните , възможност за скалиране. Теоремата на CAP доказва че за създаването на една такава система могат да се използват само два то тези три стълба. Т.е. можем да имаме система разполагаща с висока консистентност и възможност за разширяване , система с висока наличност на данните и възможност за разширяване или система с висока консистентност и висока наличност но без да може да се разширява.
Основните предимства и недостатъци на този модел са:
Предимства
- Прост и гъвкав – Релационния модел е изграден върху т.н. таблици и връзки между тях , данните , таблиците и връзките между тях са структурирани и осигуряват голяма простота при използването им. Структурата на една база от данни се нарича схема и в нея са описани всички нейни елементи без данните.
- Продуктивност при разработката на софтуер – Благодарение на простия и гъвкав модел програмистите са значително по продуктивни при използването на релационния модел , възникналите грешки се откриват бързо и лесно.
- Стандартизиран език за работа SQL – Едно от основните предимства е стандартизирания език за комуникация с БД – SQL. Въпреки множеството диалекти изродили се с времето основната концепция и синтаксис на езика се запазва. Това позволява на програмисти работили с MSSQL например бързо да се адаптират и към MySQL.
Въпреки безспорните си предимства когато става въпрос за големи обеми от данни релационния модел почва да показва слабости.
Недостатъци
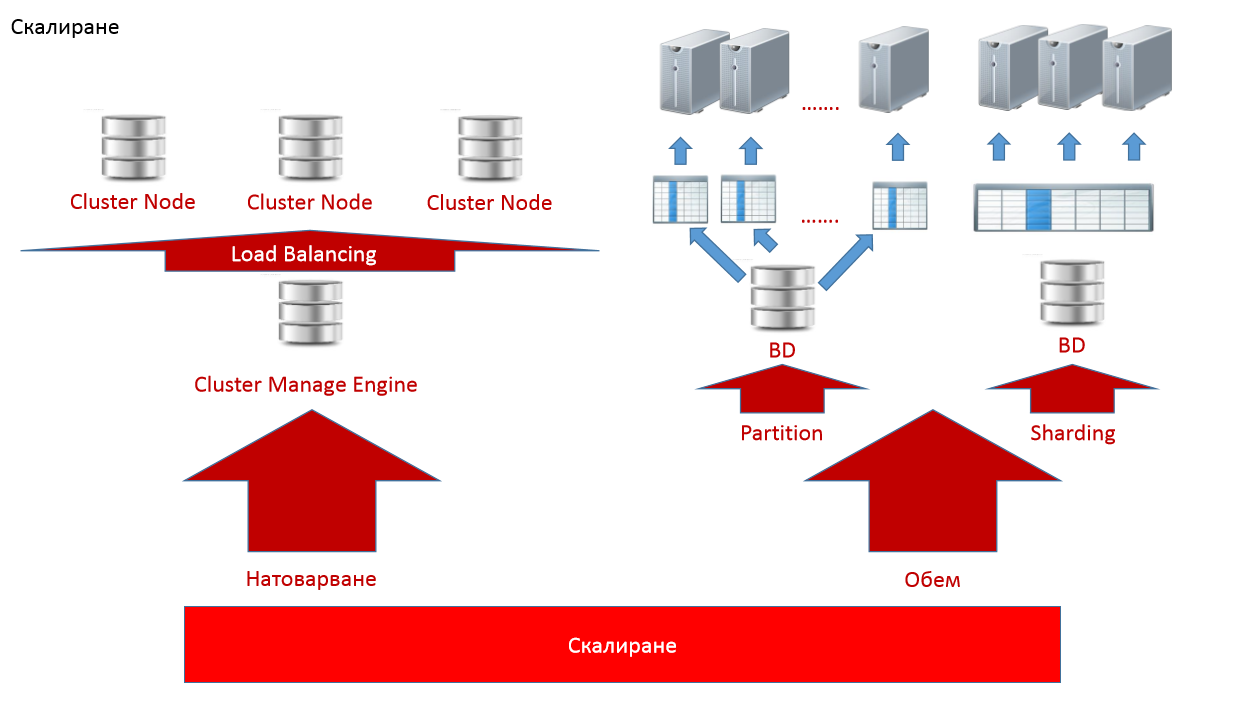
- Скалиране – Скалирането от своя страна се разделя на два типа , скалиране по натоварване и скалиране по обем. При скалирането по натоварване имаме една сравнително малка БД върху която прилагаме огромно натоварване. При големи натоварвания се стига до момент в който физическата машина върху която е разположена БД не може да се справи с натоварването. Тогава се практикува т.н. клъстеризация като натоварването се разпределя между няколко клъстерни нода. За да се постигне равномерно натоварване на всички нодове в клъстера се използва т.н. Cluster Load Balancing.
Когато става въпрос за скалиране по обем , разполагаме с една огромна БД която физически не може да се събере на една единствена машина. Тогава отново се прибягва до използването на група от сървъри за съхранението на данните като има два основни подхода. Първо Partition , БД се разделя върху няколко различни машини като на всяка машина се съхранява една или повече таблици от нея. Ако обаче една таблица е толкова голяма че не може да бъде съхранена на една машина се използва Sharding което позволява таблицата да бъде разделена и съхранявана на няколко различни машини.
- Кеширане – Характерното при кеширането е че трябва да се има в предвид какво приложение ще използва БД. Само по себе си кеширането може да увеличи значително производителността при четене на данните но не и при запис. Друг недостатък е че самото кеширане често се извежда като отделен слой в дадено решение което усложнява внедряването, поддръжката и изисква допълнителни системи.
Коментари (0)
Все още няма коментари към тази новина